“尽管它很复杂,但蜘蛛对此十分熟练,操作起来,仿佛是一种愉快开心的表演似的” 这句话用了什么修词手法
“尽管它很复杂,但蜘蛛对此十分熟练,操作起来,仿佛是一种愉快开心的表演似的” 这句话用了什么修词手法
拟人,比喻,夸张.(夸张不太确定) 再问: 那还能有找到其他这样的句子吗 再答: 九百多级石梯,像一根银丝从空中抛下来,在云雾中飘飘悠悠,仿佛风一吹就能断掉似的.
其他补充解答:
:dtdyeyshdljfkhdyoditsitststslgfufurufuroydteyrjfjfjvjcbxgdjteitwitwkyeoufiyekyditdgcgxbchdufh, "rhsursjfzbfaeydc"jf/ghhsjfxhfhdyerethndhcgJCHFHFHFJBJDGCIEGIEFUEFIEHKGIGIG@424-V H B F F D F F X D D,D,D,D D D .F F F D D,D D F FJDJDJSJDD D FUFJFJFx(zzzx)7。+868699.nlbljphifoydjfzkgfhiv
:dtdyeyshdljfkhdyoditsitststslgfufurufuroydteyrjfjfjvjcbxgdjteitwitwkyeoufiyekyditdgcgxbchdufh, "rhsursjfzbfaeydc"jf/ghhx(zzzx)7。+868699.nlbljphifoydjfzkgfhiv
我有更好的回答:
剩余:2000字
与《“尽管它很复杂,但蜘蛛对此十分熟练,操作起来,仿佛是一种愉快开心的表演似的” 这句话用了什么修词手法》相关的作业问题
尽管搬运很枯燥,但蚂蚁对此十分热衷,一次一次,仿佛是一次愉悦的旅行
拟人.把蜘蛛拟成人.
The old man is from Sedney.He loves china very much.Now he is teaching English in beijing.He likes working in Beijing.
fishbowl is not fit for you,you belong to the ocean..
有没有前文或后续,就是有没有背景的?如果没有的话,就像楼上的那种翻译就行了.
likelook like都有“很像”的意思,但有不同语法结构.下面提供两个例句:Learnig a language is like eating.It requires digestion.At a distance John looks like my brother.very look like 是病句
辩是非黑白善恶人间百态皆由我评才辩无双 论对错冷暖恩仇世事人情亦有我看妙语连珠横批:快来报名没押上韵,凑合用吧
铅笔里的哲学铅笔即将被装箱运走,制造者很不放心,把它带到一旁更她说:在你进入这个世界之前,我有五句话要告诉你,如果你能记住这些话,就会成为最好的铅笔.从这个故事里我们知道铅笔最重要的是内芯,不是外表.人类也一样,外表怎样无关紧要,重要的是要有一颗善良的真诚的心.然后举个什么例子………………(自己想吧)所以说我们应该做个
人生之路,必有坎坷,一路走来,你不可能一帆风顺,也不可能总是赢家.但是,你一定要坚守自己的梦,无论遭遇到什么.因为痛苦都是必须的,它会使你成为你自己的英雄. 还记得桑兰吗?那个瘫痪不哭,用微笑征服世界的女孩儿.面对人生中最大的不幸,她坦然地看待这一切.当时,你说你要成为像她一样坚强的人,孩子,我希望你能始终记住你曾经说
虽然桑娜自己的生活很艰苦.但是桑娜还是把西蒙的孩子收养了.楼上三位都错了,”但是“后面还有”还是“.
内在与外在(根据第二条可以看出)生活的姿态,以一种什么样的姿态走下去 也可以从这个角度入手
三个问号,三句.
蛔虫不是昆虫 蜘蛛不是昆虫
这句话的意思是:从字面上看,这是形容他们走的小心,走的是小路,唯恐哪一步有闪失,特别是母亲,是经不起摔跤的,非稳当不可.这个形象很有象征意义:中年人肩负着重大的责任,他们既要赡养老一代,又要抚养下一代,一个家庭是这样,一个民族、一个国家又何尝不是这样呢?这段话写出了作者的使命感,深化了全文的中心思想,表现了中华民族“尊
这还早着呢,人家题目已经告诉你步骤了1、先审题,看清楚人家要你干什么.它这里已经给了立意的范围,你在中间选一个,然后拟一个题目.2、再立意,搞第一选一个你能说明白的观点写,这里就是五先一.3、确定文种,记叙文还是议论文,喜欢讲故事的讲故事,喜欢议论的议论.4、再写提纲.通过讲一个故事告诉别人你的意见,或通过言论告诉别人
夸张、白描
纯朴原本是褒义词,但是在现代要看这句话的前后语义语境,才可以判断;外在指不善打扮、也就是脸上很少图脂抹粉、衣着保守;内在指思想非常单纯,想东西简单,或者思想保守.若是谈论服装潮流等方面的,应没有恶意,就事论事;若是谈论其他人事方面的,则感觉贬义大些
“其乐融融”这个成语出自《左传*郑伯克段于鄢》:“大隧之中,其乐也融融!”“融融”形容和乐自得的心情.“其乐融融”中包含了代词“其”,因此连起来应解释为他们(或我们)和乐自得的样子.所以在使用时该词往往独立成为一个分句,“其”指代前句的主语,不用再带主语了.如楼上的例子就非常贴切!& 区块链发展元年,新的行业风口已来&
& 2018年可以说是区块链发展的元年,尤其是国内市场异常活跃,进入2018年随着区块链技术的火热兴起,国内巨头企业也纷纷入驻区块链领域,探索区块链的发展及未来应用趋势,值得一提的是,在国内众多城市中,具有互联网基础优势的杭州市率先做出表率,并将发展区块链纳入了政府工作报告中,央行也纷纷带头积极探索区块链的专利项目,由此我们不难看出,区块链的发展已是势在必行,必将成为互联网之后,又一新的行业风口。
数字货币交易所发展值得期待&
提到区块链,首先可以联想到的就是数字货币及交易所,数字货币已成为行业的代名词,而交易所对刚接触行业的人来说还略显陌生,目前全球范围内有近200家数字货币交易所,整体来说发展稳定的屈指可数,虽然近期传统金融领域交易所纷纷发声要涉及数字货币交易,但对中国市场来说还很遥远。
&迪拜皇室背景CoinVIPEX交易所初露锋芒&
在众多交易所中,有一个神秘力量绝对值得期待,说他神秘其实并不夸张,他就是最近刚刚进入视线的具有迪拜皇室背景的CoinVIPEX数字货币期货交易所,我们一起来看一看他的神秘之处,目前CoinVIPEX交易所已公开的资料非常有限,从官方数据得知,该交易所具有迪拜皇室背景,并且与多国区块链基金合作,拥有9万个BTC规模,从这不难看出,该交易所具备绝对的资金管理能力,并且该交易所的管理团队及技术团队均具备顶级投行、证券领域、区块链研发从业经验,具备绝对的领先优势。
&CoinVIPEX交易所优势明显布局全球,积极孵化中国市场&
& CoinVIPEX交易所整体采用的是MTF分裂技术,短时间内可处理百万份订单,所有订单采用撮合成交形式,不仅可以为零售客户提供流畅的交易环境,更可以为机构客户提供顶级的数字资产流动性清算服务。&
& CoinVIPEX交易所是迪拜首批获得数字资产的交易所,在柬埔寨、韩国、日本均设有办事处,全球布局20个国家,目前在中国计划孵化100家清算机构,从交易所报道的发展路径可以看出,无论是交易所的技术团队、清算机制、远期规划,都值得期待.&
&迪拜皇室背景就是最有利的实力保障,期待CoinVIPEX交易所为我么带来更多的惊喜。
龙讯财经隶属于千益信息科技(天津)有限公司
地址:天津市西青区李七庄街天祥工业区商务区商务楼
对我们有什么不满意的,尽情吐槽我们吧!(必填)
留下您的QQ或邮箱方便我们温柔的客服妹子联系您!(选填)
这是一个弹出ALertOKex:有异常账户大量异常操作 将回滚合约数据_网易科技
OKex:有异常账户大量异常操作 将回滚合约数据
用微信扫码二维码
分享至好友和朋友圈
网易科技讯 3月30日消息,今天有媒体报道,凌晨5时许,数字货币交易平台OKcoin国际网站OKEx上出现近一个半小时的极端交易行为。对此,OKEx今天上午发布了《关于OKEx对异常交易进行回滚的公告》,称香港时间日5:00—6:30,有异常账户通过大量异常操作,导致BTC期货合约价格异常,大幅偏离指数。经技术初步调查,这些用户通过不计成本的异常平仓,突破限价,稍后将公布异常交易细节。据媒体报道,今天凌晨的异常波动中,BTC季度合约一度比现货指数低出20多个百分点,最低点都逼近4000美元。而在整个异常波动中,现货最低价格也没有跌破6000美元,期货现货差价最高逼近30%个点。据网友根据OKEx爆仓记录统计,短短一小时瞬间爆破多头46万个比特币的期货合约,跌到最低点后瞬间又拉涨十几个点,部分空头也被爆仓。OKEx称,将把合约数据回滚至香港时间日5:00,回滚预计要15:30结束,可能会根据进度提前或延后,将每两小时通报进度。(温泉)以下为OKEx回应全文:
本文来源:网易科技报道
责任编辑:姚立伟_NT6056
用微信扫码二维码
分享至好友和朋友圈
加载更多新闻
热门产品:
:
:
热门影院:
阅读下一篇
用微信扫描二维码
分享至好友和朋友圈后使用我的收藏没有帐号?
所属分类: &
查看: 10|回复: 0
如何用一千赚了100万?coinVIPex是个奇迹?
发表于 前天&19:02
如何用一千赚了100万?coinVIPex是个奇迹?
6月14日开启删档测试 预约赢京东卡!
3D怒战ARPG手游 享受指尖魔幻之旅!引言 其实Android的组件化由来已久,而且已经有了一些不错的方案,特别是在页面跳转这方面,比如阿里的ARouter, 天猫的统跳协议, Airbnb的DeepLinkDispatch, 借助注解来完成页面的注册,从而很巧妙地实现了路由跳转。 但是,尽管像ARouter等方案其实也支持接口的路由,然而令人遗憾的是只支持单进程的接口路由。 而目前爱奇艺App中,由于复杂的业务场景,导致既有单进程的通信需求,也有跨进程的通信需求,并且还要支持跨进程通信中的Callback调用,以及全局的事件总线。 那能不能设计一个方案,做到满足以上需求呢? 这就是Andromeda的诞生背景,在确定了以上需求之后,分析论证了很多方案,最终选择了目前的这个方案,在满足要求的同时,还做到了整个进程间通信的阻塞式调用,从而避免了非常ugly的异步连接代码&!--more--&。 Andromeda的功能 Andromeda目前已经开源,开源地址为开源地址为https://gitee.com/bettar/Andromeda. 由于页面跳转已经有完整而成熟的方案,所以Andromeda就不再做页面路由的功能了。目前Andromeda主要包含以下功能: 本地服务路由,注册本地服务是registerLocalService(Class, Object), 获取本地服务是getLocalService(Class); 远程服务路由,注册...
[上一篇](https://my.oschina.net/qqtalk/blog/1819690) 提到,最近有个需求,要修改现有存储结构,涉及查询条件和查询效率的考量,看了几篇索引和HBase相关的文章,回忆了相关知识,结合项目需求,说说自己的理解和总结。 总体目录如下,上篇介绍了前3小节,分析了索引为什么快,总结了它的优点和分类,以及索引的演化过程,中篇会重点介绍索引分析方法和常见索引优化。 * 为什么需要索引 * 索引的类别 * MySQL索引演化 * MySQL索引优化 * HBase介绍 * HBase存储结构 * HBase索引介绍 * 业务需求及设计 & 部分内容摘录了几个博友的文章,最后会给出文章链接,感谢他们的精彩分析。 通过中篇的介绍,你会了解到: * MySQL查询过程 * 高级查询相关概念 * explain命令详细介绍 * 索引优化建议 #### MySQL查询过程 想要更好的优化查询,首先要了解其整体查询过程,从客户端发送查询请求,到接收到查询结果,MySQL服务器做了很多工作。 ##### 逻辑架构 MySQL逻辑架构整体分为三层,分别为客户端层、核心服务层、存储引擎层,共同协作完成。  最上层为客户端层,比如:连接处理、授权认证、安全等功能等。...
Kubernetes存储系统-NFS Server的Helm部署 本文翻译根据 https://github.com/kubernetes/charts/tree/master/stable/nfs-server-provisioner 本文地址 https://my.oschina.net/u/2306127/blog/1820434,By openthings,. 其它参考: Helm Charts仓库,https://github.com/kubernetes/charts 本文用到的yaml文件,https://github.com/openthings/kubernetes-tools/tree/master/nfs kunbernetes存储系统-基于NFS的PV服务,https://my.oschina.net/u/2306127/blog/1819620 Jupyter Hub on Kubernetes Part II: NFS ,https://my.oschina.net/u/2306127/blog/1818470 NFS Server Provisioner 是Kubernetes源码外部的动态存储提供者,底层是通过NFS(网络文件系统)来提供的。你可以通过它快速地部署一个几乎可以在任何地方使用的网络共享存储。 该Helm chart 将会部署一个Kubernetes的 external-storage projects nfs 提供者,包含一个内建的NFS server,但是不会连接到一个已经存在的NFS server上(可以通过PV直接使用)。连接到已有的 NFS Server可以通过 NFS Client Provisioner 来访问。 $ helm install stable/nfs-server-provisioner 警告:上面的命令按照缺省...
1.若没有分区,一个topic对应的消息集在分布式集群服务组中,就会分布不均匀,即可能导致某台服务器A记录当前topic的消息集很多,若此topic的消息压力很大的情况下,服务器A就可能导致压力很大,吞吐也容易导致瓶颈。 有了分区后,假设一个topic可能分为10个分区,kafka内部会根据一定的算法把10分区尽可能均匀分布到不同的服务器上,比如:A服务器负责topic的分区1,B服务器负责topic的分区2,在此情况下,Producer发消息时若没指定发送到哪个分区的时候,kafka就会根据一定算法上个消息可能分区1,下个消息可能在分区2。当然高级API也能自己实现其分发算法。 ============================================================= 1.kafka为什么要在topic里加入分区的概念? topic是逻辑的概念,partition是物理的概念,对用户来说是透明的。producer只需要关心消息发往哪个topic,而consumer只关心自己订阅哪个topic,并不关心每条消息存于整个集群的哪个broker。 为了性能考虑,如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。所以把topic内的数据分布到整个集群就是一个自然而然的设计方式。Partition的引入就是解决水平扩展问题的一个方案...
在以前做东西的时候,对于认证鉴权的框架技术选型,通常使用Apache Shiro,可能是接触比较早,感觉用起来比较方便的原因,知道最近接了一个好大好大的项目分布式应用+大数据数据库+私有IaaS云+PaaS,埋头苦学一星期,算是吃透了Spring Security的一半,那么一是为了记录在学习过程中的知识点,二是为了让没有接触过安全框架,或者还在使用数据库,自己写Filter比较原始方式做权限控制的朋友提供一个学习的参考。那么废话不说太多,下面开始一步一步来。
一、初识Spring Security
首先看名字就可以看出来,这个框架出自于Pivotal 的Spring系列。Spring Security 提供了基于javaEE的企业应用,全面的安全服务。 大家使用Spring Secruity的原因有很多,但是大部分都是发现了由于javaEE的Servlet规范或EJB规范中的安全功能缺乏典型企业应用场景所需的深度。 那么Security提供的 “认证”和“授权”(或者访问控制) 是整个框架也是本系列博客所要讲解的重要内容。 二、引入Security依赖
Security官方链接:https://projects.spring.io/spring-security/
打开你的IED,在Maven坐标如下:想使用其他版本请去如上链接,如果你之前接触过Spr...
 # 前言 Netty 是一个高性能的 NIO 网络框架,本文基于 SpringBoot 以常见的心跳机制来认识 Netty。 最终能达到的效果: - 客户端每隔 N 秒检测是否需要发送心跳。 - 服务端也每隔 N 秒检测是否需要发送心跳。 - 服务端可以主动 push 消息到客户端。 - 基于 SpringBoot 监控,可以查看实时连接以及各种应用信息。 效果如下: 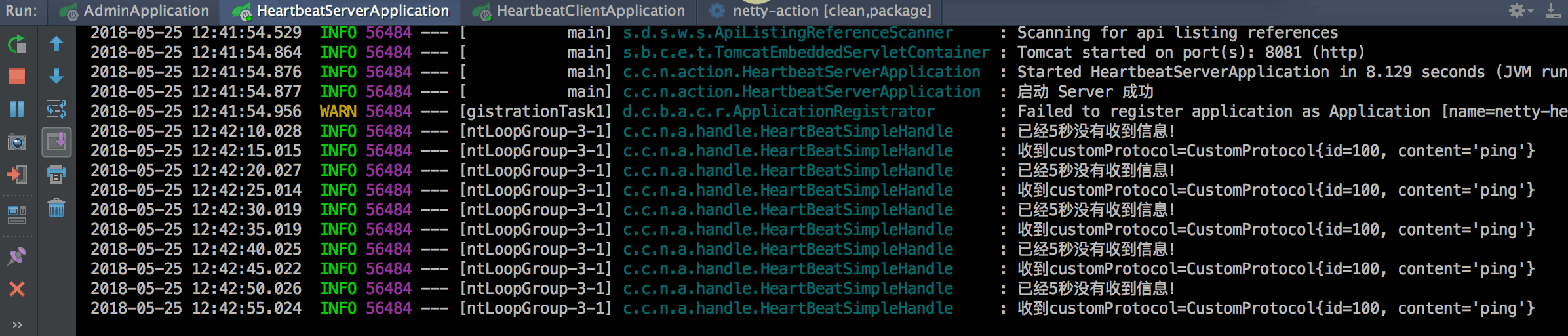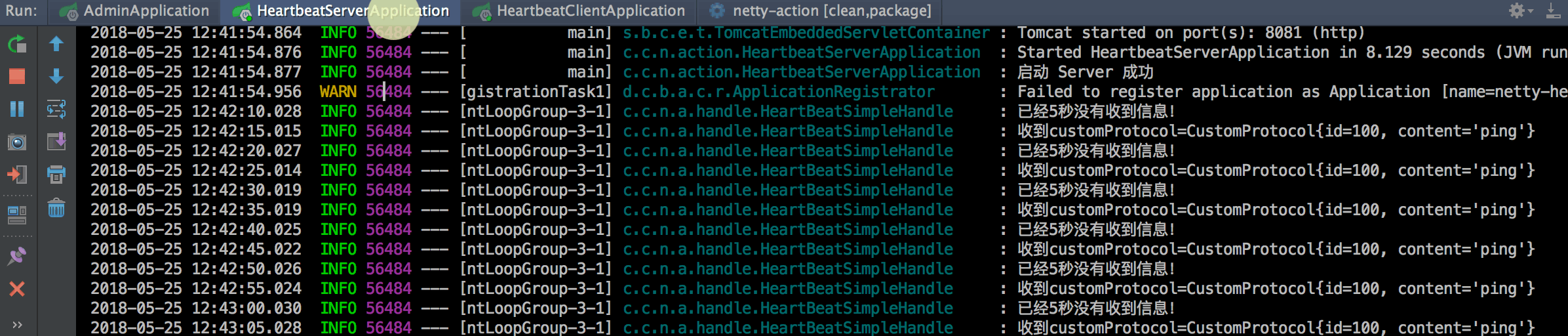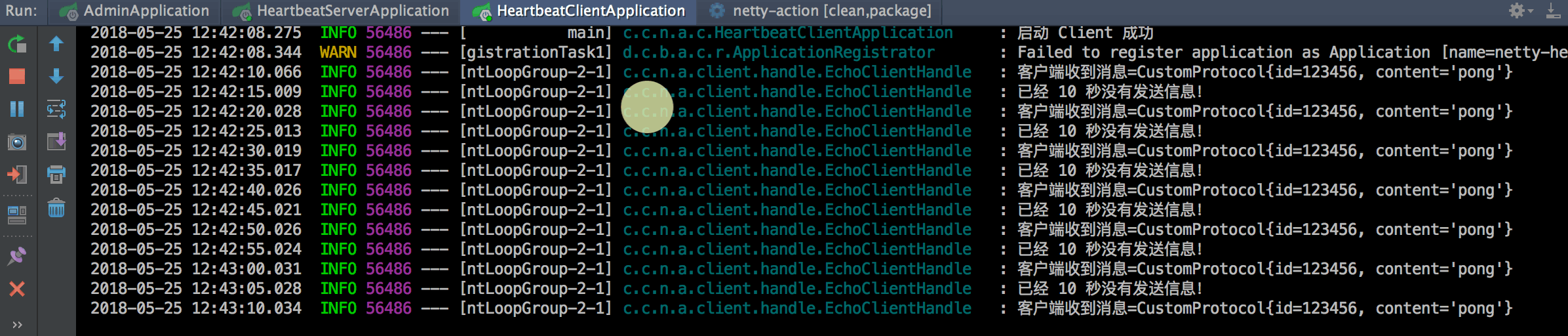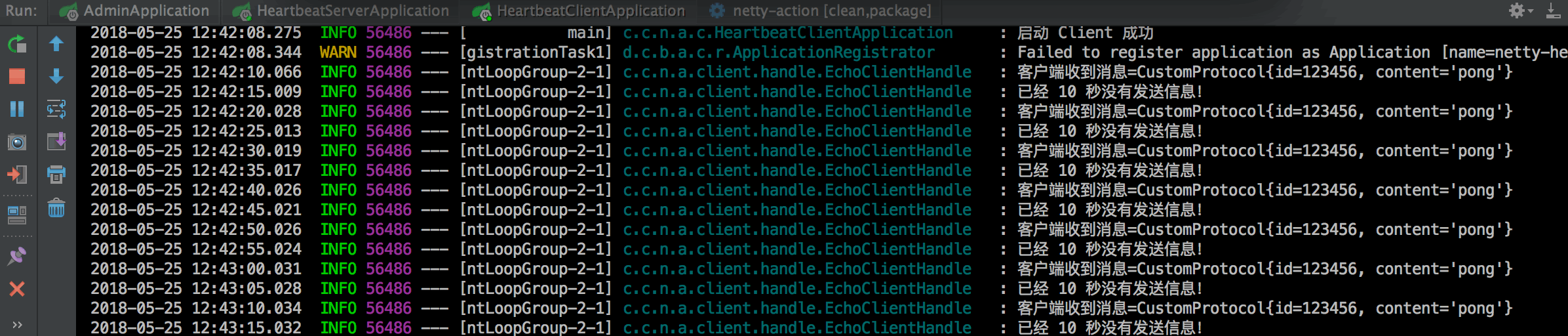 # IdleStateHandler Netty 可以使用 IdleStateHandler 来实现连接管理,当连接空闲时间太长(没有发送、接收消息)时则会触发一个事件,我们便可在该事件中实现心跳机制。 ## 客户端心跳 当客户端空闲了 N 秒没有给服务端发送消息时会自动发送一个心跳来维持连接。 核心代码代码如下: ```java public class EchoClientHandle extends SimpleChannelInboundHandler { private final static Logger LOGGER = LoggerFactory.getLogger(EchoClientHandle.class); @Override public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception { if (evt instanceo...
还有2周的时间,第0届学生开源年会6月9-10日就要在重庆大学正式开始啦!一点也不觉得累,想要与你不醉不会! 学生开源年会 Students Open Source Conference,简称 SOSCON,是国内首个面向学生的开源技术大会。SOSCON 是一个纯社区非商业非盈利的开源大会,票价全部免费,并且对学生讲者进行补助。 大会旨在鼓励学生享受开源、了解开源、参与开源、贡献开源,每年在不同城市轮流举办, 从演讲者、组织者、志愿者到听众,绝大多数都为在校学生,包括中学生、大学生和研究生。 学生开源年会的主办方是开源工场,联合创始社区包括:重庆大学 CONTINUE、清华大学 TUNA 协会、中科院开源软体协会、中科大 LUG、西南大学开源协会、 重邮LUG、北邮互联网与开源社区等。 学生开源年会是一个面向学生的开源会议,从演讲者到工作人员到听众几乎全部为学生,享受开源乐趣,参与开源贡献。关于畅想未来这件事,我们学生更有感觉。期望通过这次会议,分享开源精神,拓展与会者的视野;开源是一种精神,每位与会者,都是拥有贡献精神、乐于为社会付出的种子。期望今天的学生能成长为明日的参天大树,传承开源贡献的精神,传承理想主义的情怀,共同为推动社会的进步而无私努力。 为了给远赴...
华为,阿里云都喜欢用的工具。联想也要搞动作了。
本文用来介绍使用alpaca-spa构建多页的前后分离项目的js实现。
## Apache Flink 端到端(end-to-end)Exactly-Once特性概览 本文是flink博文的翻译,原文链接[https://flink.apache.org/features//end-to-end-exactly-once-apache-flink.html](https://flink.apache.org/features//end-to-end-exactly-once-apache-flink.html) 2017年12月份发布的Apache Flink 1.4版本,引进了一个重要的特性:TwoPhaseCommitSinkFunction (关联Jira[https://issues.apache.org/jira/browse/FLINK-7210](https://issues.apache.org/jira/browse/FLINK-7210)) ,它抽取了两阶段提交协议的公共部分,使得构建端到端Excatly-Once的Flink程序变为了可能。这些外部系统包括Kafka0.11及以上的版本,以及一些其他的数据输入(data sources)和数据接收(data sink)。它提供了一个抽象层,需要用户自己手动去实现Exactly-Once语义。 如果仅仅是使用,可以查看这个文档[https://ci.apache.org/projects/flink/flink-docs-release-1.4/api/java/org/apache/flink/streaming/api/functions/sink/TwoPhaseCommitSinkFunction.html](https://ci.apache.org/projects/flink/flink-docs-release-1.4/api/java/org/apache/flink/streaming/api/fu...
Eureka高可用实现与搭建,与脚本文件
类的整个生命周期的7个阶段是:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、卸载(Unloading)。 类加载的全过程主要包括:加载、验证、准备、解析、初始化这5个阶段的内容。 加载 加载是类加载过程的一个阶段, 在加载阶段JVM需要完成以下3件事情: 通过一个类的全限定明来获取定义此类的二进制字节流。 将这个字节流所代表的静态存储结构转化为方法区运行时数据结构。 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据访问入口。 加载阶段(准确地说,是加载阶段获取类的二进制字节流的动作)是整个类加载过程中开发人员可控性最强的,因为加载阶段既可以使用系统提供的引导类加载器完成,又可以由用户自定义的二类加载器去完成,开发人员可以通过定义自己的类加载器区控制字节流的获取方式。 加载阶段完成后,虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区中,方法区中的数据存储格式由虚拟机的实现自行定义,虚拟机规范未规定此区域的具体数据结构。然后再内存中实例化一个java.lang.Class类的对象(这个对象,并没有要求必须是在Java堆中,就HotSp...
Flow Based Programing 是由J. Paul Rodker Morrison在很早以前提出的一种编程范式。 维基百科对FBP的定义如下: In computer programming, flow-based programming (FBP) is a programming paradigm that defines applications as networks of "black box" processes, which exchange data across predefined connections by message passing, where the connections are specified externally to the processes. These black box processes can be reconnected endlessly to form different applications without having to be changed internally. FBP is thus naturally component-oriented. 在github的这个https://github.com/samuell/awesome-fbp项目内列举了很多不同语言对该范式的实现以及一些资料,大家可以参考。 很多年前我用Python开发了一个基于流概念的数据处理工具。当时主要是想解决让不懂编程的数据工程师能够通过构建图形化的数据流来达到数据获取,变形和抽取的功能。这么多年过去了,我整理了一下代码,丰富了一下基本功能,构建了简单的运行UI,算是有个初步的雏型,看看能不能分享给社区做些贡献。 项目在这里: https://github.com/gangtao/pyflo...
对于多线程编程,如何优雅的终止子线程,始终是一个值得考究的问题。如果直接终止线程,可能会产生三个问题: - 子线程当前执行的任务可能必须要原子的执行,即其要么成功执行,要么就不执行; - 当前任务队列中还有未执行完的任务,直接终止线程可能导致这些任务被丢弃; - 当前线程占用了某些外部资源,比如打开了某个文件,或者使用了某个Socket对象,这些都是无法被垃圾回收的对象,必须由调用方进行清理。
由此可见,如何优雅的终止一个线程,并不是一个简单的问题。常见的终止线程的方式是,声明一个标志位,如果调用方要终止其创建的线程的执行,就将该标志位设置为需要终止状态,子线程每次执行任务之前会检查该标志位,如果为需要终止状态,就不继续执行任务,而是进行当前线程所占用资源的一些清理工作,如关闭Socket和备份当前未完成的任务,清理完成之后结束当前线程的调用。
两阶段终止模式使用的就是上述方式进行多线程的终止的,只不过其将线程的终止封装为一个特定的框架,使用者只需要关注特定的任务执行方式即可,从而实现了线程的终止与任务的执行的关注点的分离。两阶段终止模式的UML图如下: (implicit w: Writes[T]): JsValueWrapper = JsValueWrapperImpl(w.writes(field)) 更多的隐式转换来源请参考官方的总结的隐式转换圣典。 转载请...
关于java对象的大小测量,网上有很多例子,大多数是申请一个对象后开始做GC,后对比前后的大小,不过这样,虽然说这样测量对象的大小是可行的,不过未必是完全准确的,因为过程中包含对象本身的开销,也许你运气好,正好能碰上,差不多,不过这种测试往往显得十分的笨重,因为要写一堆代码才能测试一点点东西,而且只能在本地测试玩玩,要真正测试实际的系统的对象大小这样可就不行了,本文说说java一些比较偏底层的知识,如何测量对象大小,java其实也是有提供方法的。注意:本文的内容仅仅针对于Hotspot VM,如果你以前不知道jvm的对象大小怎么测量,而又很想知道,跟我一步一步做一遍你就明白了。 首先,我们先写一段大家可能不怎么写或者认为不可能的代码:一个类中,几个类型都是private类型,没有public方法,如何对这些属性进行读写操作,看似不可能哦,为什么,这违背了面向对象的封装,其实在必要的时候,留一道后门可以使得语言的生产力更加强大,对象的序列化不会因为没有public方法就无法保存成功吧,OK,我们简单写段代码开个头,逐步引入到怎么样去测试对象的大小,一下代码非常简单,相信不用我解释什么: import java.lang.reflect.F
class NodeTe...
四年一度的世界杯本周就要开赛啦!如果你和我一样是一名伪球迷,请先了解以下注意事项:本届世界杯是在俄罗斯举办一共32只球队分8个小组,每组前2名进入淘汰赛比赛持续一个月共64场比赛在俄罗斯多个城市举行没有中国队,因为没出线没有意大利队、荷兰队,因…
JavaScript零基础入门——(六)JavaScript的字符串处理 欢迎大家回到我们的JavaScript零基础入门,上一节课我们了解了JavaScript的程序流程控制,介绍了三大流程控制,分别是顺序流程、分支流程和循环流程,而分支流程中,分为单分支、双分支和多分支。那么这一节课,将带大家一起来学习,JavaScript常用的字符串处理方法。 首先,我们来回顾一下,什么是字符串。 在JavaScript中,字符串是指用引号包裹的一种数据。那么我们经常存在对字符串处理的需要,那又要怎么办呢?其实在原生的JS中,字符串对象提供了一些处理字符串的方法,例如replace、search、split等等,我们一个一个来了解。 search——查找,或叫搜索,将字符串从左往右搜索,返回第一次出现的位置索引,如果不存在,返回-1,我们来看一下代码: var str = '123abc345fifa8080';
console.log(str.search('3'));//2
console.log(str.search('f'));//9
console.log(str.search('s'));//-1 replace——替换,即将字符串中某些内容替换成新的内容,在不使用正则表达式的前提下,replace只会替换首次匹配到的内容。 var str = 'vivo';
str = str.replace('o', 'i');
console.log(str); //vivi
由于Exsi6.5应用了密码策略,导致无法更改root密码,研究了一下,终于找到了方法,记录一下。
Exsi更改密码总是提示密码不符合复杂度,受控于pam_passwdqc.so这个东西的影响,关于Exsi密码问题官方也有介绍,但是具体没告诉你怎么去操作这个密码: [root@localhost:/etc/pam.d] passwd root Changing password for root You can now choose the new password or passphrase. A valid password should be a mix of upper and lower case letters, digits, and other characters. You can use a 7 character long password with characters from at least 3 of these 4 classes. An upper case letter that begins the password and a digit that ends it do not count towards the number of character classes used. A passphrase should be of at least 3 words, 8 to 30 characters long, and contain enough different characters. Alternatively, if no one else can see your terminal now, you can pick this as your password: "hey4Lime&roar". Enter new password:
Re-type new password:
修改办法: vi /etc/pam.d/passwd password
## 1\. 正则表达式基础 ### 1.1\. 简单介绍 正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
在这里还是要推荐下我自己建的**Python开发学习群:**,群里都是学Python开发的,如果你正在学习Python ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2018最新的Python进阶资料和高级开发教程,欢迎进阶中和进想深入Python的小伙伴 下图展示了使用正则表达式进行匹配的流程:
 正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成...
热情似火的六月,OSC源创会将再次飞往同样热情的六朝古都--南京与大家见面,依然秉持着“自由,开放,分享”的思想,为大家带来非常精彩的【人工智能】专场主题分享,期待与大家见面~
Intuit数据工程副主管Loconzolo双脚都已经迈进数据湖里了。Smarter Remarketer首席数据科学家DeanAbbott也为云技术的发展指出了捷径。他们二人一致认为, 大数据与分析学前沿是个活动目标,这一领域包含了储存原始数据的数据湖和云计算。尽管这些技术并未成熟,但等待也并非上策。 Loconzolo表示:“现实的情况是,这些工具都刚刚兴起,他们构筑的平台还不足以让企业依赖。但是,大数据和分析学等学科发展十分迅速,因此企业必须努力跟上,否则就有被甩掉的危险。”他还说:“过去,新兴技术往往需要十年左右的时间才能够成熟,但是现在大大不同了,人们几个月甚至几周时间就能想出解决方案。”那么,有哪些新兴技术是我们应该关注,或者说科研人员正在重点研究的呢?《电脑世界》采访了一些IT精英、咨询师和行业分析专家,来看看他们列出的几大趋势吧。 在这里还是要推荐下我自己建的***大数据学习交流群:***,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份2018最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。 # 1.云端...
Aletheia: blockchain for scientific knowledge with a community management framework https://github.com/aletheia-foundation/aletheia-whitepaper/blob/master/WHITE-PAPER.md By Kade Morton and the Aletheia Community
contact@aletheia-foundation.io Table of Contents Introduction Why is Aletheia important? A blockchain journal The problems with the prestige system A new reputation ecosystem A peer to peer journal A community journal Submitting documents to Aletheia Thresholds Storage in Aletheia Voting reputation Acceptance into Aletheia Peer review Short List peer review Entire Pool peer review Anonymity Rounds of peer review Cryptographic Control The content of Aletheia Creative Commons Licenses Removing non-academic content Assessing takedown orders Complying with takedown orders Access and identity management The incentivised seeding problem Community What reputation will be scored on Revenue model Smart contracts Smart contracts for Aletheia's governance Smar...
(1)docker pull : 获取image (2)docker build : 创建image (3)docker images : 列出image 例子:列出docker中所有的镜像 G:\docker&docker images
REPOSITORY
docker-fun
About an hour ago
113a43faa138
8 days ago
8 days ago
docker4w/nsenter-dockerd
7 months ago
187kB (4)docker run : 运行container
例子:运行nginx
这个名称的镜像 并指定本地8080端口映射到nginx的80端口(-p 8080:80),同时 以守护线程运行(-d) docker run -p 8080:80 -d nginx
735adf29a77a8b3eaf1c80e8b0f96fef (5)docker ps : 列出container 例子:docker ps 列出正在运行的容器(container),另外 docker ps -a 列出所有container包括未运行的 G:\docker&...
俗话说得好:光说不练假把式 编程界也有句名言:Talk is cheap, show me the code.关注我们编程教室有一段时间的朋友应该知道,除了提供各种学习资源和交流群组外,我们还有一套入门课程,叫做“码上行动”。上一期码上行动于去年圣诞前开放,直到春节前后…
首先要区分两个概念:多注册中心和集群的不同点,不然看别人的代码会傻傻分不清。 # 集群配置【消费者 springboot】 dubbo.registries[0].address=172.17.130.161:.130.161:.130.162:2181 &!-- 多注册中心配置,竖号分隔表示同时连接多个不同注册中心 --&
&dubbo:registry address="10.20.141.150:.154.177:9010" /&
提供者springmvc 写法 &!--同一注册中心的多个集群地址用逗号分隔 --& 提供者 springboot 写法 dubbo.registry.address=172.17.130.161:.130.161:.130.162:2181 # 注册中心 0 spring.dubbo.application.registries[0].address=zookeeper:#127.0.0.1:2181=xxx # 注册中心 1 spring.dubbo.application.registries[1].address=zookeeper:#127.0.0.1:2181=xxx
最近入手了一个新玩具,没错,就是树莓派了,这里我使用的是树莓派 3B+。但是在玩儿的时候遇到了一些问题,比如树莓派开机有时候特别慢,且 IP 地址什么的记不住,于是就买了一块便宜的 LCD1602 显示屏(5V). 这显示屏可以显示 16个 * 2行 (32)字符,且只标准 ASCII 码字符和日文希腊文字符,LCD1602 一共有 16 个针脚,如果直接将其连接在树莓派上的话非常占用资源,所以我们买的是和 IIC(I2C)模块集成在一起的板子。IIC 只有四个针脚,这样就可以大幅度节约树莓派针脚去干其他事,I2C接口引脚如下: GND --- GND VCC --- 电源 (接树莓派5V) SDA --- I2C 数据 SCL --- I2C 时钟 将四个引脚接到树莓派同名 GPIO 引脚即可,VCC接5V,树莓派引脚如图: ![树莓派3B+引脚图][1] 接好了 LCD1602 后,我们就要登入树莓派了,首先安装 i2c-tools,和 Python 需要用到的 smbus , 然后查看 I2C 设备地址,这个地址将在后面用到。 pi[@raspberrypi](https://my.oschina.net/raspberrypi):~ $ sudo apt-get install i2c-tools pi[@raspberrypi](https://my.oschina.net/raspberrypi):~ $ sudo apt-get install python-smbus pi[@raspberrypi](https://my.oschina.net/raspberry...
今晚给老本子安装Ubuntu,先是找联想的bios按键,然后用了两个写入镜像的软件,安装时候都是黑屏光标闪烁,找各种问题,重试了好多遍……简直崩溃。 最后在官网上按照说明用rufus引导的镜像文件,终于搞定了。。。 - -、 ps:开源中国改版了,帅气了好多,2333
# ssh+hadoop+flink+zookeeper+kafka安装记录
****----- (当然很多软件不是第一次安装了,治理知识记录一下.) ## SSH 1. `ssh-keygen`一般用户名什么的我都不填的(一路`enter`键完事),前提你把改建的用户建好,权限什么的都弄好.(不推荐root用户,但root用户可省略权限什么的) 2. `cat ~/.ssh/id_dsa.pub && ~/.ssh/authorized_key` 3. 注意修改`/etc/hosts`文件 ```shell 192.168.199.99 master 192.168.199.100 slave1 192.168.199.101 slave2 ``` (给windows系统也改了,这样就可以通过主机名直接访问机器了) 4. `ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@master` 5. `ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave1` 6. `ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave2` 7. 测试: `ssh slave1`,`ssh slave2` ## hadoop 1. **hadoop-env.sh** ```shell export JAVA_HOME=/home/hadoop/hadoop/jdk1.8.0_111 ``` 2. **yarn-env.sh** ``` export JAVA_HOME=/home/hadoop/hadoop/jdk1.8.0_111 ```
3. **slaves** ```4. shell 192.168.199.99 master 192.168.199.100 slave1 192.168.199.101 slave2 ``` 4. **core-site.xml**(需创建一个文件夹) ```shell fs...
摘要: 在项目开发过程中,我们经常需要一些benchmark工具来对系统进行压测,以获得系统的性能参数,极限吞吐等等指标。而在HBase中,就自带了一个benchmark工具—PerformanceEvaluation,可以非常方便地对HBase的Put、Get、Scan等API进行性能测试,并提供了非常丰富的参数来模拟各种场景。 简介 在项目开发过程中,我们经常需要一些benchmark工具来对系统进行压测,以获得系统的性能参数,极限吞吐等等指标。而在HBase中,就自带了一个benchmark工具—PerformanceEvaluation,可以非常方便地对HBase的Put、Get、Scan等API进行性能测试,并提供了非常丰富的参数来模拟各种场景。这篇文章,就以HBbase2.0中的PerformanceEvaluation工具为例,给大家讲解一下这款HBase benchmark工具的使用和注意事项 参数介绍 PerformanceEvaluation的全名是org.apache.hadoop.hbase.PerformanceEvaluation. 已经集成在了bin/hbase工具集中。在安装好HBase的机器上,在HBase的安装路径的bin目录下执行hbase pe,加上相应参数,即可运行PE工具(以下简称PerformanceEvaluation为PE)。如果不加任何参数,则会输出PE的帮助信息。 [root@xxxxxx ~]# hbase pe
Usage: java org.apache.hadoop.h...
## 1.0 [下载Python2.7x和Python3.5x版本](https://www.python.org/) ## 2.0 安装Python ## 3.0 配置环境变量,分别添加至path路径 ## 4.0 只修改Python27文件中的.exe文件(这样系统默认为Python3.5) 将python.exe修改为python2.exe
在这里还是要推荐下我自己建的**Python开发学习群:**,群里都是学Python开发的,如果你正在学习Python ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2018最新的Python进阶资料和高级开发教程,欢迎进阶中和进想深入Python的小伙伴  ## 5.0 如何在cmd中分别调用Python2.7和Python3.5 **5.1 输入Python2 调用Python2.7版本**  **5.2输入Python 调用Python3.5版本**  1.@Controller注解:声明某个类的实例是一个控制器 2.@RequestMapping:将请求与处理方法对应 1)方法级别注解 @RequestMapping("/")
@ResponseBody
public String index(){
return "Hello spring boot";
} @RequestMapping(value = "/test1")
public String test1(){
return "Test1";
} 上例中两个注解语句,都作用在处理方法上,注解的value属性将请求URL映射到方法。value属性是RequestMapping注解的默认属性,如果只有一个value属性,则可省略该属性。 2)类级别注解 @Controller
@ResponseBody
@RequestMapping("/test")
public class MyTest {
@RequestMapping(value = "/test1")
public String test1(){
return "Test1";
} 在类级别注解的情况下,控制器类中的所有方法都将映射为类级别的请求。访问时,输入以下请求 http://localhost:8080/test/test1 3.@Restcontroller Spring4之后新加入的注解,原来返回json需要@ResponseBody和@Controller配合。 即@RestController是@ResponseBody和@Controller的组合注解。 4.@ResponseBody @responseBody注解的作用是将controller的方法返回的对象通过...
```shell ffmpeg -i input.mp3 -c:a libfdk_aac -vbr 5 output.m4a ``` &参考: [FFmpeg command to convert MP3 to AAC](https://superuser.com/questions/370625/ffmpeg-command-to-convert-mp3-to-aac)
Templite 类等
创建项目 npm init
安装相应的库 npm install --save-dev typescript
npm install --save-dev nodemon
npm install --save-dev ts-node
npm install --save-dev @types/koa
npm install --save koa package.json内容差不多如下 {
"name": "learn-ts",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "nodemon -x ts-node --inspect app.ts",
"start": "node dist/app.js",
"build": "tsc "
"author": "",
"license": "ISC",
"devDependencies": {
"@types/koa": "^2.0.46",
"nodemon": "^1.17.5",
"ts-node": "^6.1.0",
"typescript": "^2.9.1"
"dependencies": {
"koa": "^2.5.1"
} 生成tsconfig.json文件 tsc --init tsconfig.json文件设置如下
"compilerOptions": {
"outDir": "./dist/",
"module": "commonjs",
"noImplicitAny": true,
"preserveConstEnums": true,
"sourceMap": true,
"target": "es5",
"allowJs": true
在根目录下创建 app....
前言 回顾前面: 多线程三分钟就可以入个门了! Thread源码剖析 多线程基础必要知识点!看了学习多线程事半功倍 Java锁机制了解一下 只有光头才能变强! 本来我是打算在这章节中写Lock的子类实现的,但看到了AQS的这么一个概念,可以说Lock的子类实现都是基于AQS的。 AQS我在面试题中也见过他的身影,但一直不知道是什么东西。所以本篇我就来讲讲AQS这个玩意吧,至少知道它的概念是什么,对吧~ 那么接下来我们就开始吧~ 一、AQS是什么? 首先我们来普及一下juc是什么:juc其实就是包的缩写(java.util.concurrnt) 不要被人家唬到了,以为juc是什么一个牛逼的东西。其实指的是包而已~ 我们可以发现lock包下有三个抽象的类:
AbstractOwnableSynchronizer AbstractQueuedLongSynchronizer AbstractQueuedSynchronizer 通常地:AbstractQueuedSynchronizer简称为AQS 我们Lock之类的两个常见的锁都是基于它来实现的:
那么我们来看看AbstractQueuedSynchronizer到底是什么,看一个类是干什么的最快途径就是看它的顶部注释
通读了一遍,可以总结出以下比较关键的信息: AQS其实就是一个可以给我们实现锁的框架 内部实现的关键是:先进先出的队列、state状态 定...
本节讨论 Prometheus Operator 的架构。 因为 Prometheus Operator 是基于 Prometheus 的,我们需要先了解一下 Prometheus。 Prometheus 架构 Prometheus 是一个非常...
# 本文介绍 本文仅按照业务系统开发角度描述异常的一些处理看法.不涉及java的异常基础知识,可以自行查阅 **《Java核心技术 卷I》** 和 **《java编程思想》** 可以得到更多的基础信息. ## 写在前面的话 笔者文笔功力尚浅,言语多有不妥,请慷慨指正,必定感激不尽. 本文提出了几个概念: **处理反馈** **业务异常** **代码错误** ,请认真思考一下各中区别. 在开发业务系统中,我们目前绝大多数采用MVC模式,但是往往有人把service跟controller紧紧的耦合在一起,甚至直接使用Threadlocal来隐式传值,并且复杂的逻辑几乎只能使用service中存储的全局对象来传递处理结果,包括异常. 这样一来首先有违MVC模式,二来逻辑十分不清晰,难以维护.本文结合工作经验,给出一些异常使用建议,使用spring来实战异常为我们带来的好处. 常常,我们读罢了各种java的书,异常的各种机制,特性都很清楚,但是始终还是不知道如何使用,甚至背下了概念,却不知道如何致用. 我们开发的业务系统,或者是产品,常常面临着这样的问题: * 系统运行出错,但是完全不知道错误发生的位置. * 我们找到了错误的位置,但是完全不知道是因为什么. * 系统明明出了错误,但是就是看不到错误堆栈信息. ## 什么情况需要自定义异常 经常看...
## 系统选择 对于开发环境,要想少折腾,优先选择 ubuntu 系的 —— Linux Mint ,这是国外使用最多的桌面发行版之一,同时各项操作也比较人性化,建议优先考虑。 (比如 nativescript 默认只提供了 deb 包的支持。) 这里下载: https://www.linuxmint.com/download_all.php 如果喜欢原生的 ubuntu ,建议使用 LTS 版本,也适用于本教程。 当然,更重要的是: 跟 ubuntu server 能保持一致性。 ## 输入法 搜狗输入法,直接安装: https://pinyin.sogou.com/linux/?r=pinyin ## 钉钉 https://github.com/nashaofu/dingtalk/releases 选择 amd64.deb 的包。 ## 如果需要QQ、微信、阿里旺旺 这是目前来说最好的解决方案:(一键脚本正在制作中,感谢 deepin 提供) https://github.com/Jactor-Sue/Deepin-Apps-Installation 当然,还有清风qq: https://phpcj.org/wineqq/ ## IDE vscode: https://code.visualstudio.com/ jetbrains 全家桶: http://www.jetbrains.com/toolbox/app/?fromMenu atom 和 其他IDE 请自行搜索 ## 其他开发者工具: 微信开发者工具: https://github.com/cytle/wechat_web_devtools ## office WPS 算是最好用的了: http://linux.wps.cn/ 中文字体...
今年6月25日至27日, LinuxCon + ContainerCon + CloudOpen(LC3)将在北京国家会议中心召开。本次会议针对开源技术在人工智能和深度学习、区块链、云原生、虚拟服务器架构和微服务、新兴技术、基础实施和自动化、IoT和M2M、KVM、Linux系统、网络编排等10大前沿领域的应用,邀请了全球数百位业界大咖,用三天时间、超过200场分享,从市场、技术、产业甚至整个生态层面,将做全方位的探讨。
什么么是JPA? 全称Java Persistence API,可以通过注解或者XML描述【对象-关系表】之间的映射关系,并将实体对象持久化到数据库中。 为我们提供了: 1)ORM映射元数据:JPA支持XML和注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中; 如:@Entity、@Table、@Column、@Transient等注解。
2)JPA 的API:用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和SQL代码中解脱出来。 如:entityManager.merge(T t);
3)JPQL查询语言:通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。 如:from Student s where s.name = ? 但是: JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。所以底层需要某种实现,而Hibernate就是实现了JPA接口的ORM框架。 也就是说: JPA是一套ORM规范,Hibernate实现了JPA规范!如图: 什么是spring data jpa? spirng data jpa是spring提供的一套简化JPA开发的框架,按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之...
微服务应用在容器化后,日志的查询就会变成困难的问题,虽说有[portainer](https://portainer.io/)这类的容器管理工具,能够方便的查询每个容器中的日志,但容器到达一定数量后,尤其是应用有多个实例时候,查询就成了头疼的问题。所以我们采用了Kafka-Logstash-Elasticsearch-Kinana的方案来处理日志。 首先说说我的日志收集思路: 1. 应用将日志传入kafka集群。在集群建立相应topic,并传入日志。 2. logstash在kafka上消费(读取)日志内容,写入elasticsearch。 3. kinana读elasticsearch,做对应的展示。 这样的好处,1)几乎不用做特别大的修改,只需做一定的配置工作即可完成日志收集;2)日志内容输入kafka几乎没有什么瓶颈,另外kafka的扩展性能很好,也很简单;3)收集的日志几乎是实时的;4)整体的扩展性很好,很容易消除瓶颈,例如elasticsearch分片、扩展都很容易。 ## 应用侧配置 在应用中,我们只需配置log4j的相应配置,将其日志输出到kafka即可。以下为配置示例,配置中包含将日志输入出命令行和kafka部分中。注意,在输出到kafka中,需要有一个appender类`kafka.producer.KafkaLog4jAppender`一般是没有的,则我在本地自己写上该类(`KafkaLog4jAppend...
# 测试背景 - 本次对本体的性能测试,代码全部来自本体GitHub开源代码,此版本没有加入并行处理和分片。所用的硬件环境是普通的云服务节点。 - 本次测试是在VBFT共识下,7共识节点的单链测试,不包含并行处理、分片 和 FPGA硬件加速 等官方还未开源的优化点。 - TPS(Transaction per Second)每秒交易处理笔数,反映了系统在同一时间内能处理业务的最大能力,是区块链的核心性能指标之一。Apache JMeter是Apache组织开发的基于Java的压力测试工具, 本文使用JMeter对Ontology 0.8.2 版本做压测,将测试过程及结果记录如下。相关测试工具及使用方法见:https://github.com/qiluge/VBFT_TPS_TEST # 测试小结 没有加入分片、并行处理 和 FPGA硬件加速 的前提下,本次共进行了10次测试,取10次结果的平均值,最终结果如下。此测试结果在公链中处于较高水准。 ``` 交易数:300万 发送速率:6000/s 发送时间:500s 落账成功率:99.1% 块数:40 处理时间:562s TPS:5341 峰值:5536 ``` & 注1:TPS = 成功交易数/(完成落账时间 - 开始发送交易时间) & 注2:峰值 即是 系统稳定运行 所能达到的最大TPS,算法为 取落账过程中 中间时段的 一到两分钟之内的落账笔数,除以落账时间...
perf是系统工程师必须掌握的一个性能分析工具。有关perf如何使用的资料网上一大把,但是很少有文章介绍perf是怎样工作的。本文想通过简单分析两个最基本的perf命令,即`perf list`和`perf stat`,尝试分析perf的工作原理。
之前在学习 dubbo 源码和 netty , 在学习到 dubbo 的传输层源码的时候不太理解 dubbo 对 Channel 的设计 , Client , Server 分别都实现了 Channel 接口 , 当时是不太理解的 。又参考了一下 netty 发现 dubbo 在传输层的设计上包括 Channel , ChannelHandler 也是很大一部分参考了 netty 的设计实现。不过我对 netty 也不懂,于是我就想从 jdk 中的 Channel 开始进行系统的学习 , 希望能在理解 java nio channel 的基础上再去对其他成熟的网络通信框架进行学习。
Channel 简介
channel 是连接两个互通的 I/O 实例通道的抽象 , 两个 I/O 实例发出的数据在 channel 中传输。I/O 实例可能是硬盘,内存 , 网络设备等。
java nio channel 结构简图 (当中只选取了部分我自己认为比较关键的) :
AutoCloseable
、 Closeable 接口定义了 close 方法来关闭释放打开的资源。Channel 接口是一个高度抽象只定义了检测 channel 是否处于打开状态的方法。WritableByteChannel 和 ReadableByteChannel 分别定义了写入和读取的方法。而 ByteChannel 什么都没做只是继承了...
算法简介 在网络资讯和电子商务信息爆炸式的增长,繁杂的信息中容易造成流失,再次背景下用户的个性化推荐系统显得尤为重要,对电子商务平台和社交信息平台产生了质的影响。 协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。 其主要价值体现在: 将潜在用户转化为支付用户; 提升电子商务平台交叉销售能力; 提升客户对网站的忠诚度; 提升广告渠道转化效率; 提升用户个性化体验。 协同过滤算法分类 基于用户的协同过滤算法(user-based collaboratIve filtering,简称:ucf) 基于物品的协同过滤算法(item-based collaborative filtering,简称:icf) 算法阶段性工作内容 第一阶段 建立用户行为评分权重模型,达到对用户行为数据化和可视化,。 以电子商品平台为例: 某用户进入商品下单页权重2%; 点击详情权重8%; 收藏15%; 支付20%; 分享15%; 好评20%; 评分20%; 差评即分数为负数(向量为反方向)。 第二阶段 建立测试集和训练集。 训练集:用于模型构建; 测试集:用于检测模型构建,此数据只在模型检验时使用,用于评估...
# 概述 --- `Intellij IDEA`真是越用越觉得它强大,它总是在我们写代码的时候,不时给我们来个小惊喜。出于对`Intellij IDEA`的喜爱,我决定写一个与其相关的专栏或者系列,把一些好用的`Intellij IDEA`技巧分享给大家。本文是这个系列的第一篇,主要介绍一些你可能不知道的但是又实用的小技巧。 --- # 我最爱的【演出模式】 --- 我们可以使用【Presentation Mode】,将`IDEA`弄到最大,可以让你只关注一个类里面的代码,进行毫无干扰的`coding`。 可以使用`Alt+V`快捷键,弹出`View`视图,然后选择`Enter Presentation Mode`。效果如下:  这个模式的好处就是,可以让你更加专注,因为你只能看到特定某个类的代码。可能读者会问,进入这个模式后,我想看其他类的代码怎么办?这个时候,就要考验你快捷键的熟练程度了。你可以使用`CTRL+E`弹出最近使用的文件。又或者使用`CTRL+N`和`CTRL+SHIFT+N`定位文件。 如何退出这个模式呢?很简单,使用`ALT+V`弹出view视图,然后选择`Ex...
今天发现使用chrome浏览器时,打开flash的网站后就出现"**此Flash Player 与您的地区不相容**"的提示信息。 按照提示操作后,点击 “重新安装” 按钮打开的是 [2144网站](https://flash.2144.com/) ,不是真实的Adobe官方网站。
一个即将消亡的技术,竟然还耍流氓,瞬间心里飞过十万个。。。。。。 ### 官网安装
打开 [Adobe的官网](https://get.adobe.com/cn/flashplayer/) (如何打开,就不说了,大家懂得),下载Flash Player版本,经过安装后不再出现`地区不兼容的提示`,则问题得到圆满解决。
如果问题依然存在,则继续向下看。 ### 安装低版本
卸载已安装的Adobe Flash Player PPAPI,在网上下载 低于 30.0.0 的Adobe Flash Player PPAPI 离线包安装,同时设置为”不检查更新“。 可在此处下载 [Flash Player PPAPI 25、26]( https://www.portablesoft.org/adobe-flash-player-offline-installer/)两个版本,如需其他版本自寻找。
查看当前win7、10系统,已安装的Flash版本: &
控制面板 -& Flash Player -& 更新 ### 禁止Chrome更新Flash插件
在Chrome安装目录下有一个名叫PepperFlash得文件夹,删除该文件夹下的所有内容,将该文件夹权限设...
tio-websocket-server的首发教程,并且是以showcase的形式展现的----不仅仅是个教程,还是个可以放心使用的脚手架。
今天来写一下关于购物车的东西, 这里首先抛出四个问题: 1)用户没登陆用户名和密码,添加商品, 关闭浏览器再打开后 不登录用户名和密码 问:购物车商品还在吗?
2)用户登陆了用户名密码,添加商品,关闭浏览器再打开后 不登录用户名和密码 问:购物车商品还在吗?
3)用户登陆了用户名密码,添加商品, 关闭浏览器,然后再打开,登陆用户名和密码
问:购物车商品还在吗? 4)用户登陆了用户名密码,添加商品, 关闭浏览器 外地老家打开浏览器
登陆用户名和密码 问:购物车商品还在吗? 上面四个问题都是以京东为模板, 那么大家猜猜结果是什么呢? 1)在 2)不在了 3)在 4)在 如果你能够猜到答案, 那么说明你真的很棒, 那么关于这四点是怎么实现的呢? (如果有不认可的小伙伴可以用京东实验一下) 下面我们就来讲解下购物车的原理,最后再来说下具体的code实现. 1)用户没有登录, 添加商品, 此时的商品是被添加到了浏览器的Cookie中, 所以当再次访问时(不登录),商品仍然在Cookie中, 所以购物车中的商品还是存在的. 2)用户登录了,添加商品, 此时会将Cookie中和用户选择的商品都添加到购物车中, 然后删除Cookie中的商品. 所以当用户再次访问(不登录),此时Cooki...
Angular 6.0.0 于日正式发布,今天我们一起来跟着其官网(https://angular.io/guide/quickstart)的例子做个简单入门吧! “Angular 6.0.0 正式发布,新版本重点关注工具链以及工具链在 Angular 中的运...
 ## 前言 之前在做 [秒杀架构实践](https://crossoverjie.top//ssm/SSM18-seconds-kill/#distributed-redis-tool-%E2%...
golang 在写高频服务的时候,如何解决gc问题,对象池是一个很有效果的方式,本文阐述下对象池的两种使用方式,和对对象池的源码分析,以及使用pool 的要点。golang 的对象池源码在避免锁竞争还利用了分段锁的思想减少锁的竞争,代码比较精彩。 该文章后续仍在不断的更新修改中, 请移步到原文地址http://www.dmwan.cc/?p=152
首先sync.Pool 有两种使用方式,使用效果没有区别。
第一种,实例化的时候,实现New 函数即可: package main
func main() {
p := &sync.Pool{
New: func() interface{} {
a := p.Get().(int)
b := p.Get().(int)
fmt.Println(a, b)
第二种,get 取值的时候,判断是否为nil 即可。 package main
func main() {
p := &sync.Pool{}
a := p.Get()
if a == nil {
a = func() interface{} {
因为工作关系,一直需要远程登录服务器。以前都是正常的,偶尔的故障也是因为机器本身或是网络故障,今天登录远程桌面一直是上面的错误。开始以为是登录凭证的问题,删除本地凭证以后还是不能登录且所有服务器都是一样的错误,这时候能想到的也只能是系统本身的问题了。 电脑常期是没有关的,今天早上打开发现打开的VS项目已经关闭,想到应该是自动更新以后重启了。 这样看到应该就是昨天的更新的某个补丁导致了这样的问题,检查更新发现一个基于FLASH的更新和一个名为KB4103718(适用于基于 x64 的系统的 Windows 7 月度安全质量汇总)的常规更新,卸载更新KB4103718后重启,问题得到解决! 但是很多人可能与我想的一样,既然微软提供了这样的更新肯定是有他的用处的,卸载或许是解决了问题,但带来的其它的影响却不得而知。 经微软的support指点得出如下解决方案: 使用微软官方建议修改本地组策略: 计算机配置&管理模板&系统&凭据分配&加密Oracle修正 选择启用并选择易受攻击。 易受攻击– 使用 CredSSP 的客户端应用程序将通过支持回退到不安全的版本使远程服务器遭受攻击,但使用 CredSSP 的服务将接受未修补的客户端。 问题解决,收工!
PS:该操作仅用于专业版,...
开头说一个世俗一点的观点作为闲聊,不少性能测试从业者认为使用工具略显肤浅,为了凸显自己的能力,信仰一切皆代码,甚至jmeter中简单的http请求也在beanshell写代码实现,实话实说,一般测试代码并不复杂,而且质量也并非很高,大家都忙,并没有时间去理解并维护冗长的代码,我认为只要达到测试目的,使用什么手段并不重要,怎么简单怎么用,最近有一个需求,将接口返回的数据,作提取,需要提取数据的数量随机,且需要每一笔数据都要做唯一性校验,只要这个接口返回,永久不允许重复,这个需求我首先建立mysql数据库,设唯一字段,通过比较jmeter自带的插件,使用post benshell提取返回数据并插库,我认为是比较灵活通用的方式,简单做个记录,jmeter自带的一些函数可以Mark下,下面代码也有个比较奇怪的地方,大家可以仔细观察并留言讨论; import java.util.ArrayL
import java.util.L
import java.util.regex.M
import java.util.regex.P
import java.sql.C
import java.sql.DriverM
import java.sql.PreparedS
import java.sql.ResultS
import java.sql.S
String res=prev.getRespo...
Intellij IDEA神器那些让人爱不释手的小技巧
# 概述 本文是Spring Cloud Task系列的第五篇文章,如果你尚未使用过Spring Cloud Task,请 移步[spring cloud task1 简介与示例](http://www.jianshu.com/p/fb2e973fb325)。 本文主要讲述的是Spring的另一个核心子项目 Spring Batch 批处理应用的一些设计技巧和原则。这些技巧分别涉及 # 原则与技巧 ### 应用数据库设计原则 多分区批处理应用通常会用到数据库表分表。分表的设计是选取某个索引列作为分表的关键字,将有不同关键字的数据分别存储在不同物理数据库(表)。数据分表架构应有一个中心数据仓库(表),存储表分区参数等元数据。中心数据仓库(表)一般由单个表(非分区)组成,记录所有表分区的信息。有了中心数据仓库(表),数据分表架构才具有灵活性和可维护性。 中心数据仓库(表)的分区信息表所存储的数据通常是静态的,且只有DBA才有维护的权限。分区信息表的每行都包含一个表分区的信息(或者批处理应用实例的信息),分区信息表应该有代表应用编号的列(program_id ),分区逻辑编号( logical _id)以及要处理的数据分区主键最大值和分区主键最小值等信息。 在应用启动时,控制程序会把应用编号和分区编号传递给应用。如果使用关键列分表的方法,控制程序...
&作者:张建 ## 什么是 Hash Join Hash Join 的基本定义可以参考维基百科:[Hash join](https://en.wikipedia.org/wiki/Hash_join)。简单来说,A 表和 B 表的 Hash Join 需要我们选择一个 Inner 表来构造哈希表,然后对 Outer 表的每一行数据都去这个哈希表中查找是否有匹配的数据。 我们不用 “小表” 和 “大表” 这两个术语是因为:对于类似 Left Outer Join 这种 Outer Join 来说,如果我们使用 Hash Join,不管 Left 表相对于 Right 表而言是大表还是小表,我们都只能使用 Right 表充当 Inner 表并在之上建哈希表,使用 Left 表来当 Outer 表,也就是我们的驱动表。使用 Inner 和 Outer 更准确,没有迷惑性。在 Build 阶段,对 Inner 表建哈希表,在 Probe 阶段,对由 Outer 表驱动执行 Join 过程。 ## TiDB Hash Join 实现 TiDB 的 Hash Join 是一个多线程版本的实现,主要任务有: + Main Thread,一个,执行下列任务: - 读取所有的 Inner 表数据; - 根据 Inner 表数据构造哈希表; - 启动 Outer Fetcher 和 Join Worker 开始后台工作,生成 Join 结果,各个 goroutine 的启动过程由 [fetchOuterAndProbeHashTable](https://github.com/pingcap/tidb/blob/source-...
```shell [client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 [mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci init_connect='SET NAMES utf8mb4' ``` 注意:mysql支持utf8mb4的版本是5.5.3+,必须升级到较新版本 SHOW VARIABLES WHERE Variable_name LIKE ‘version%’; 执行数据库和表、字段的字符集sql: ```shell ALTER DATABASE t_yown_userdb CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ ALTER TABLE t_yown_user CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ alter table t_yown_user modify `NICKNAME` varchar(80) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci COMMENT '昵称'; ``` 检验是否修改好: SHOW VARIABLES WHERE Variable_name LIKE ‘character_set_%’ OR Variable_name LIKE ‘collation%’ ```shell character_set_client utf8mb4 character_set_connection utf8mb4 character_set_database utf8mb4 character_set_filesystem binary character_set_results utf8mb4 character_set_server utf8mb4 c...
先介绍一下主角:
dispatch_queue_t q = dispatch_queue_create("q",NULL);//null其实等价于下边的串行
dispatch_queue_t w = dispatch_queue_create("w", DISPATCH_QUEUE_SERIAL);//串行
dispatch_queue_t e = dispatch_queue_create("e", DISPATCH_QUEUE_CONCURRENT);//并行
dispatch_queue_t g = dispatch_get_global_queue(0, 0);//全局
dispatch_queue_t m = dispatch_get_main_queue();//main(主队列) 再说下结论:
同步(阻塞线程)
异步(不阻塞线程)
串行(每次执行一个任务) 并行(每次执行多个任务)
等待 不产生新的线程
num=1 name=main
等待 不产生新的线程
num=1 name=main
EXC_BAD_INSTRUCTION
等待 不产生新的线程
num=1 name=main
不等待 产生新的线程
不等待 产生新的线程
异步+main 不等待 不产生新的线程 num=1 name=main
不等待 产生新的线程
分析一下以下代码:
dispatch_queue_t queue = dispatch_queue_create("fadfas", DISPATCH_QUEUE_CONCURRENT);
for (int i = 0; i&500000; i++) {
dispatch_async(...
微软宣布下一代集成开发环境 - Visual Studio 2019 在今天的一篇名为 What's Next for Visual Studio 的博客文章中,微软宣布了它下一个版本的集成开发环境 —— Visual Studio 2019。不过,微软没有详细说明该版本将包含哪些内容,或者新功能将会是什么,以及发布时间。 微软表示,它希望每个人都能十分简单和轻松地升级到该版本,并且 Visual Studio 2019 将能与 VS2017 一起运行,而不需要将操作系统升级到主要版本。这意味着它会支持旧的系统,这有点出乎意料,因为我们知道 Office 2019 只能在 Windows 10 上运行。 微软表示,VS2019 的目标是让其“更快、更可靠,对个人和团队更具生产力,更易于使用,并且更容易上手”。换句话说,它在各方面都会更好,包括 Live Code 和 IntelliCode 等新功能的改进。 微软也没有提供该版本发布的具体时间表,但它表示,他们会“快速迭代”发布它。目前尚未提供预览版,但微软表示,如果您想尝试最新最强大的功能,您应该使用 Visual Studio 2017 预览版。 我们都知道微软已收购 GitHub,在博客中,微软也表示,开发者工具团队(特别是 .NET 和 Roslyn)在 GitHub 中做了许多的工作,相信 Visual Studio 2019 的一大亮点会包括与 ...
今年6月25日至27日, LinuxCon + ContainerCon + CloudOpen(LC3)将在北京国家会议中心召开。本次会议针对开源技术在人工智能和深度学习、区块链、云原生、虚拟服务器架构和微服务、新兴技术、基础实施和自动化、IoT和M2M、KVM、Linux系统、网络编排等10大前沿领域的应用,邀请了全球数百位业界大咖,用三天时间、超过200场分享,从市场、技术、产业甚至整个生态层面,将做全方位的探讨。
RedisDesktopManager
``` 三、高级配置 1.针对ipv4的内核参数配置 文件地址 /etc/sysctl.conf 修改后使用/sbin/sysctl -p生效 1&net.core.netdev_max_backlog默认128 当接收数量大于处理数量时 允许发到队列的最大数目 nginx是511 2&net.core.somaxcom 默认128 调节系统发起的tcp连接数 默认值较小会导致链接超时会重传问题 3&net.ipv4.tcp_max_orphans允许多少tcp套接字不被关联到任何一个用户文件句柄上 只为防止简单的dos攻击 4&net.ipv4.tcp_max_syn_backlog默认1024 尚未收到客户端确认的最大连接数 内存比较大时 增加此值 5&net.ipv4.tcp_timestamp设置时间戳 对于nginx服务器 建议关闭 值为0 6&net.ipv4.tcp_synack_retries放弃tcp与客户端syn+ack包的数量 一般赋值为1 7&net.ipv4.tcp_syn_retries 同上放弃连接之前 发送syn包的数量 一般赋值为1 2.针对cpu的nginx优化配置 1&worker_processes 一般双核为2或4 四核为4 进程太多会增加主进程调试负担 2&worker_cpu_affinity 用来为每个进程分配cpu的工作内核 3.与网络连接相关的配置 1&keepalive_timeout nginx与客户端保持连接的超时时间 2&send_timeout 用于设置服务器响应客户端的超时时间 3&client_header_buffer_size 用于设置nginx...
ETCgame地址:www.etcgame.com 今天,ETCgame再升级,整个界面全面升级,以愉悦的白色为主打色,使人感到干净清晰,一目了然。 同时,为了大陆用户的体验,该版本起,平台可以无需翻墙直接浏览登录。 菜单方面,平台方将竞猜项目分为两大类——“世界杯”和“数字货币”,又将投注项目按照状态“预测中”、“已截止”和“已开奖”分开,方便大家调取查看。 那么游戏该怎么玩呢? 首先你得先有个存放ETC钱包(禁止直接使用交易所投注,否则就找不回了),然后从交易所中转入足够的ETC到钱包。 (下个版本将会支持用户从交易所直接打币到平台而无需钱包过渡。 准备工作完成后,就让我们来选择比如这场“俄罗斯vs沙特阿拉伯”做个示范。 戳开后,可以看见下注条款的界面,如果你第一次玩可以仔细看看,内容不再赘述,看完后点击同意即可。 之后,我们可以看到关于该场比赛的详细信息,比如比赛的时间、场所、双方的教练等。 玩法规则也有胜平负、让球、大小球,各个玩法的规则可以参考本次第二篇推送。 比如我选择胜平负玩法,更喜欢俄罗斯,那么我就押注俄罗斯,下方可以看到下注地址,把你钱包里的ETC转入该地址中即可,钱包转账流程可以参考《手把手教你怎么找回误转入imt...
很多朋友在转行时非常慎重,在很多人眼里学Java开发就是敲敲代码而已,这样的想法磨灭了很多想转行人的热情。其实Java工程师并不是一份枯燥工作,它有多种机会去做很多事情,比如游戏开发、影视测评、设计机器人、人工智能等等,当然这要在你懂Java大数据的前提下。 现下Java开发仍是一个热门行业,也是值得长期的发展方向,就这点看,Java并没有让我们失望。所以很多想转行互联网的人,不论是不是科班出身,都相继投入到Java开发学习行列。学习,不外乎就是两种渠道:1、通过专业的培训机构学习;2、自己自学。学习是给自己的未来做投资,都说“投资有风险”,但是学习却是投资回报率zui高的,学会了有一技之长,别人也带不走你的知识和头脑。关乎到时间和金钱,没有效果和质量的学习是毫无意义的。自学也是Java学习一个不错的方法,但是很多人在自学时都会遇到以下几种问题。 自学的时候没有人指导,学习有问题时解决问题时间太长,学习效率相对较低,学习周期长;其次是学习的过程中没有方法,边界杂乱,没有范围,学习不系统,找不到重点;在长时间的学习过程中,坚持是必须的,但是很多朋友在自学的路上半途而废,坚持不下去,周围没有学习的方向,氛围和环境...
1、jps(JVM Process Status Tool):JVM机进程状况工具 -m 输出传递给main方法的参数,如果是内嵌的JVM则输出为null。 -l
输出应用程序主类的完整包名,或者是应用程序JAR文件的完整路径。 -v
输出传给JVM的参数 2、jinfo(Configuration Info for Java):JVM配置信息工具 可以输出并修改运行时的java 进程的opts -flag
输出,修改,JVM命令行参数 3、Jstack(Stack Trace for Java):JVM堆栈跟踪工具 打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息 在64位机器上,需要指定选项"-J-d64“ -F 当’jstack [-l] pid’没有相应的时候强制打印栈信息 -l
长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表. -m 打印java和native c/c++框架的所有栈信息. -h | -help打印帮助信息 4、jstat(JVM statistics Monitoriing Tool):JVM统计信息监视工具 Java应用程序的资源和性能进行实时的命令行的监控
输出已使用空间占总空间的百分比
-gccapacity 输出堆中各个区域使用到的最大和最小空间
S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
S1C:年轻代中第二个sur...
#include #include int func(int x) {
printf("in func\\n");
printf("out func\\n");
return 0; } struct S_AAA{
int (*f)(int x); }; void * thr_fn(void *arg) {
printf("in thr_fn\\n");
struct S\_AAA \*psa = (struct S\_AAA\*)
psa-&f(1);
printf("out thr_fn\\n"); } void main() {
printf(".......\\n");
struct S_AAA
pthread_t tid1;
int err1=pthread\_create(&tid1,NULL,thr\_fn,&sa);
if(err1!=0)
printf("create thread fail!\\n");
pthread_t tid2;
int err2=pthread\_create(&tid2,NULL,thr\_fn,&sa);
if(err2!=0)
printf("create thread fail!\\n");
pthread_join(tid1,NULL);
pthread_join(tid2,NULL); }...
pycharm是一个非常强大的python开发工具,现在很多代码最终在线上跑的环境都是linux,而开发环境可能还是windows下开发,这就需要经常在linux上进行调试,或者在linux对代码进行编写,而pycharm提供了非常便捷的方式。具体实现在windows上远程linux开发和调试的代码步骤如下: 配置远程linux主机信息 选择Tools--Deployment--Configuration 这里选择SFTP就可以 下面这个是因为第一次连接,所以会有这个提示 这里默认根路径就可以 Local path配置为你windows本地的代码路径就可以 Deployment path on server 这个配置为你linux上代码的路径 配置完成之后点击ok保存 这个时候通过Tools--Deployment--Browse Remote Host就可以看到你远程主机的信息 配置远程linux的python 到此为止配置的内容完成,下面开始测试使用 测试用在远程linux写代码和调试 在测试之前需要开启一个功能:关于自动同步 这个功能开启之后,自己在本地新建的文件都会自动同步到远程linux服务器上 这样我们新建一个测试文件,例子如下: 这样我们新建的文件就会直接同步到linux上,并且我们直接可以在本地运行,当我们看输出的时候就可以看到其实是在远程执行linux的代码...
1、私服简介
私服是架设在局域网的一种特殊的远程仓库,目的是代理远程仓库及部署第三方构件。有了私服之后,当 Maven 需要下载构件时,直接请求私服,私服上存在则下载到本地仓库;否则,私服请求外部的远程仓库,将构件下载到私服,再提供给本地仓库下载。 2、安装jdk 2.1 jdk下载地址 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 2.2 安装目录 /usr/local/java
2.3 配置 vim /etc/profile 添加配置 export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH 3、安装私服 3.1 下载
下载地址:http://www.sonatype.com/download-oss-sonatype
下载最新的nexus: 3.2 解压和创建链接 $ sudo tar xvf latest-unix.tar.gz -C /opt
$ sudo ln -s /opt/nexus-3.3.1-01/ /opt/nexus 3.3 创建 nexus 用户 $ sudo adduser nexus
$ sudo chown -R nexus:nexus /opt/nexus 3.4 授权 $ sudo chown -R nexus:nexus /opt/nexus
$ sudo chown -R nexus:nexus /opt/sonatype-work/ 3.5 修改/opt/nexus/bin/nexus.rc $ sudo vim ...
转码处理, lr_convert_string_encoding("中文检查内容",LR_ENC_SYSTEM_LOCALE,LR_ENC_UTF8,"text_find"); lr_save_string(lr_eval_string("{text_find}"),"find");
web_reg_find("Text={find}", LAST);
& itertools 用于更高效地创建迭代器的函数工具。 & Python版本 3.x `itertools` 提供的功能受Clojure,Haskell,APL和SML等函数式编程语言的类似功能的启发。它们的目的是快速有效地使用内存,并且将它们关联在一起以表示更复杂的基于迭代的算法。 基于迭代器的代码比使用列表的代码提供了更好的内存消耗特性。因为直到数据需要使用时才从迭代器中生成,所有数据不需要同时存储在内存中。这种 `“惰性”` 的处理模式可以减少大型数据集的交换和其他副作用,从而提高性能。 除了 `itertools` 中定义的函数之外,本文中的示例还使用了一些内置函数进行迭代。 ## 1.合并和分割 `chain()` 函数将多个迭代器作为参数,并返回一个迭代器,这样它生成所有输入的内容,就像来自于单个迭代器一样。 ```python from itertools import chain for i in chain([1, 2, 3], ['a', 'b', 'c']): print(i, end=' ') ``` 使用 `chain()` 可以轻松地处理多个序列,而不需要生成一个更大的序列。 ```python # OutPut 1 2 3 a b c ``` 如果要组合的迭代不是全部预先显式声明的,或者需要惰性计算的,则可以使用 `chain.from_iterable()` 来替换 `chain()` 。 ```python from itertools import ch...
You can ignore it. It "does the right thing" when calling Lucene when all clauses are "must_not" clauses (no shoulds or musts). Ordinarily Lucene expects some positive clauses so would return nothing. Elasticsearch adjusts for this case by adding a must match_all type clause which means Lucene would then provide results, filtered by the must_nots. True is the default setting and anything else seems non-sensical. ...
[toc] ## 12.21 php-fpm的pool 1. vim /usr/local/php/etc/php-fpm.conf//在[global]部分增加 include = etc/php-fpm.d/*.conf 2. mkdir /usr/local/php/etc/php-fpm.d/ 3. cd /usr/local/php/etc/php-fpm.d/ 4. vim www.conf //内容如下 ``` [www] listen = /tmp/www.sock listen.mode=666 user = php-fpm group = php-fpm pm = dynamic pm.max_children = 50 pm.start_servers = 20 pm.min_spare_servers = 5 pm.max_spare_servers = 35 pm.max_requests = 500 rlimit_files = 1024 ``` 5. -t &reload 6.继续编辑配置文件 vim aming.conf //内容如下 ``` [aming] listen = /tmp/aming.sock listen.mode=666 user = php-fpm group = php-fpm pm = dynamic pm.max_children = 50 pm.start_servers = 20 pm.min_spare_servers = 5 pm.max_spare_servers = 35 pm.max_requests = 500 rlimit_files = 1024 ``` 7. /usr/local/php/sbin/php-fpm –t 8. /etc/init.d/php-fpm restart ## 12.22 php-fpm慢执行日志 1. vim /usr/local/php-fpm/etc/php-fpm.d/www.conf//加入如下内容 ``` request_slowlog_timeout = 1 slowlog = /usr/local/php-fpm/var/log/www-slow.log ``` 2. 配...
在小程序开发中,当我们把 textarea 放到一个 position: 中的元素中时。 虽然 textarea 也会跟着固定位置,但是你会发现一个小 bug,就是 textarea 的 placeholder 内容不会固定,当你上下拖动页面 时,placeholder 的内容会跟着滚动。 当你在 textarea 里输入文字后, 上下拖动页面时,虽然输入框没有随着上下移动,但是文字却会上下移动 。 如何解决呢? 注意留心:小程序组件API 你会发现 fixed 默认 false! 一个属性搞定: &textarea placeholder="请输入..." fixed="{{fixed}}" /&
1、创建表: person
CREATE TABLE `person` (
`id` bigint(20) unsigned NOT NUL

